티스토리 뷰
소개
안녕하세요:) 지마켓에서 데이터로 여러 가지 흥미로운 개발을 하고 있는 한한주입니다.
이번에 소개해 드릴 내용은 탐색적 데이터 분석 흔히 EDA(Exploratory Data Analysis)라고 불리는 분석기법에 대한 내용입니다.
처음 정제되지 않은 대용량 데이터를 마주하면 정신이 혼미해 지기 쉽습니다^^; 이럴 때 데이터 형태를 정의하고 탐색적 분석을 통해 시각화하면 좀 더 친근하게 데이터 분석을 시작할 수 있습니다.
그럼 Start!
EDA란?
위키백과에 따르면 EDA는 미국의 저명한 통계학자가 창안한 자료 분석 방법론입니다. 기존의 통계학이 정보의 추출에서 가설 검정 등에 치우쳐 자료가 가지고 있는 본연의 의미를 찾는데 어려움이 있어, 이를 보완하고자 주어진 자료만 가지고도 충분한 정보를 찾을 수 있도록 여러 가지 탐색적 자료 분석 방법을 개발하였는데요. 대표적인 예로 박스 플롯을 들 수 있습니다. 탐색적 자료 분석을 통하여 자료에 대한 충분한 이해를 한 후에 모형 적합 등의 좀 더 정교한 모형을 개발할 수 있습니다.
데이터의 종류
본 블로그에서는 데이터의 종류를 총 2가지로 나누어 탐색해 보도록 하겠습니다.
- 수치형 데이터
- 값이 수치로 측정되는 데이터
- 예) 키, 몸무게
- 범주형 데이터
- 값이 범주의 형태로 측정되는 데이터
- 예) 지역, 성별
수치형 데이터
값이 수치로 측정되는 데이터로 연속과 이산형으로 나눌 수 있습니다
- 연속형: 정수와 실수 등 특정 범위 안에 어떠한 값도 가질 수 있는 데이터
- 이산형: 정수형 데이터만 포함하는 데이터
수치형 데이터 탐색
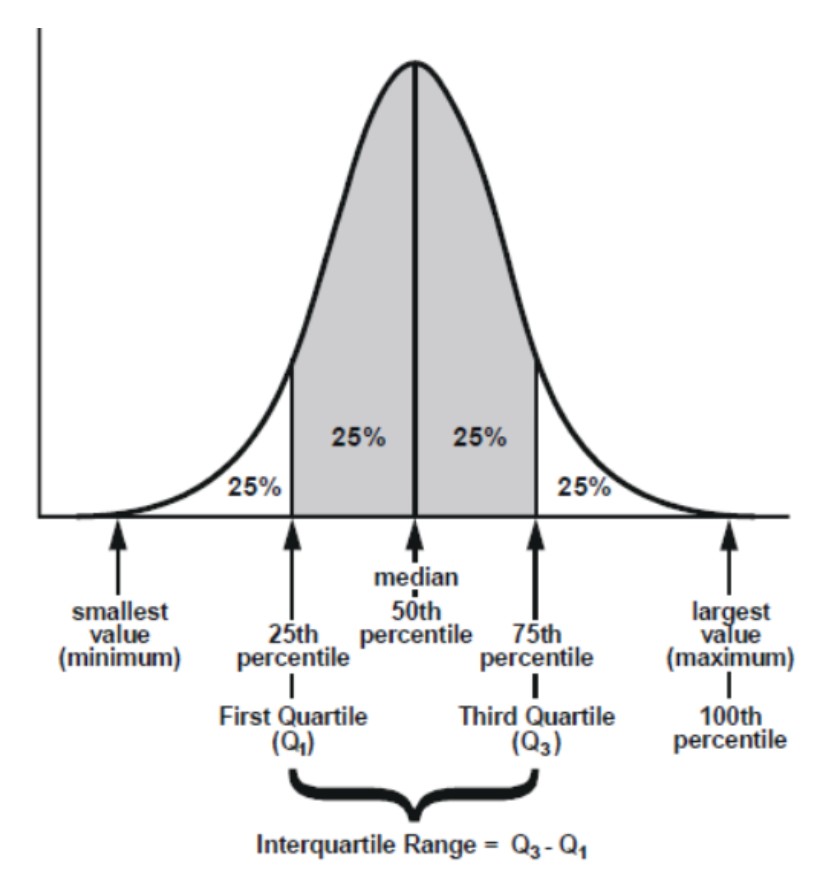
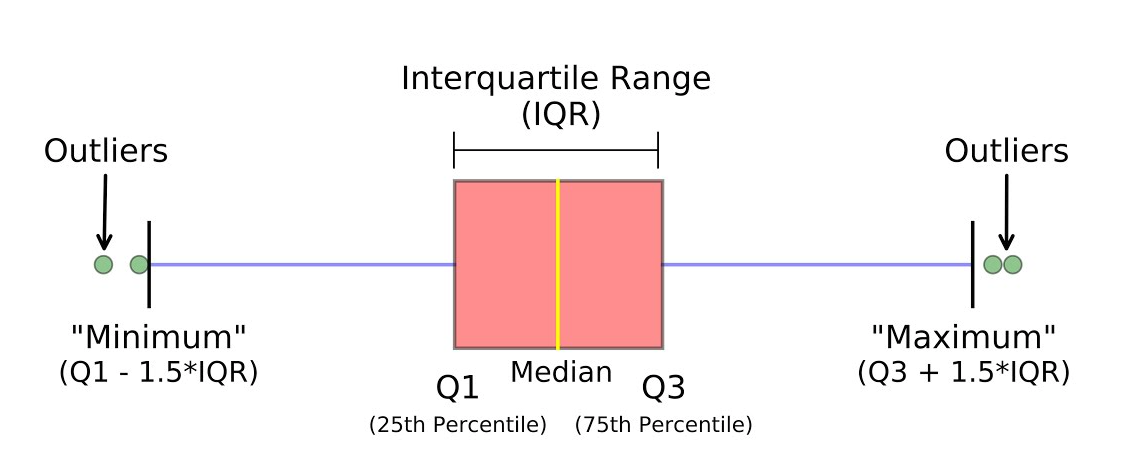
- 다섯 수치 요약
- 최솟값
- 제1사분위수: (25 Percentile에 해당하는 값)
- 제2사분위수: (50 Percentile에 해당하는 값, 중앙값)
- 제3사분위수: (75 Percentile에 해당하는 값)
- 최댓값
- 다섯 수치 요약 해석
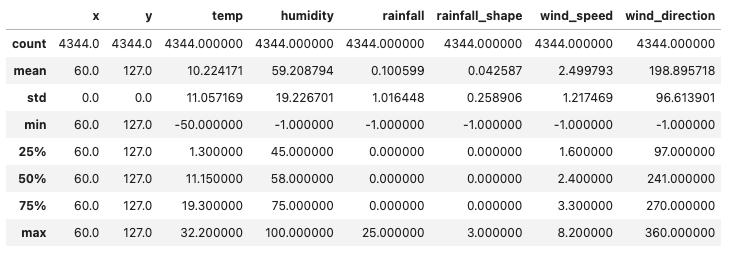
파이썬 예제
- describe() 함수를 통해 다섯 수치 요약 및 Count, Std(표준편차)의 값을 쉽게 파악할 수 있습니다.
-
df.describe() -
그래프
- Boxplot
- 이상치 및 다섯 수치 요약을 시각적으로 쉽게 파악할 수 있습니다.
-
import pandas as pd import seaborn as sns import matplotlib.pyplot as plt sns.boxplot(x = "temp", data = df_f) plt.show() -
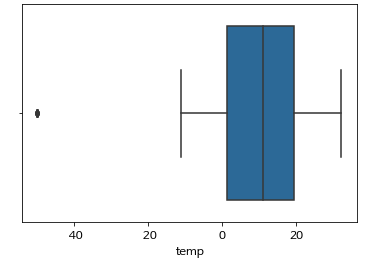
- 위 그래프를 보면 40 이상이 이상치라는 것과 4분위수에 대해 한눈에 파악할 수 있습니다.
- Boxplot 해석
- Histogram
- 도수 분포표를 시각적으로 쉽게 파악할 수 있습니다.
-
import pandas as pd import seaborn as sns import matplotlib.pyplot as plt sns.distplot(df_f['temp']) plt.show() -
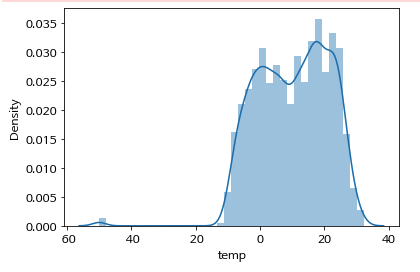
- 위 그래프를 통해 어떤 범위에 값들이 주로 분포하고 있는지에 대한 파악이 쉽게 가능합니다.
범주형 데이터
값이 범주로 구분되는 데이터로 순위형과 명목형으로 나눌 수 있습니다.
- 순위형: 범주간 순서가 의미 있는 데이터
- 명목형: 범주간 순서가 의미 없는 데이터
범주형 데이터 탐색
- 범주별 사이즈 탐색
파이썬 예제
- value_counts() 함수를 사용해 범주별 count를 쉽게 파악할 수 있습니다.
-
import pandas as pd df_total['add2'].value_counts() -

그래프
- Bar
-
import pandas as pd import seaborn as sns import matplotlib.pyplot as plt sns.barplot(data=df_yo[:5], x="add2", y="count") plt.show() -
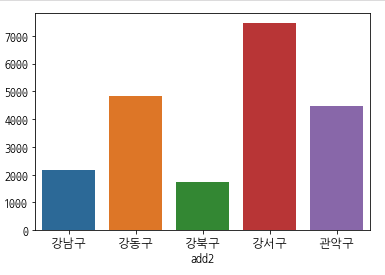
- 각 범주별 개수를 쉽게 파악할 수 있습니다.
-
- Pie
-
import pandas as pd import seaborn as sns import matplotlib.pyplot as plt colors = sns.color_palette('pastel')[0:5] plt.pie(df_yo[:5]['count'], labels = df_yo[:5]['add2'], colors = colors, autopct='%.0f%%') plt.show() -
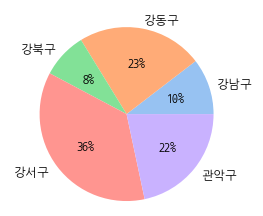
- 데이터가 차지하는 비율을 한눈에 파악할 수 있습니다.
-
마무리
익숙하지 않은 데이터를 처음 접했을 때 당황하는 경우가 많이 있는데요. 이렇게 데이터 타입을 수치형 또는 범주형으로 나누어 시각적으로 표현하면 데이터를 분석하는 데 있어 도움이 많이 됩니다.
읽어주셔서 감사합니다:)
Reference
'Infra' 카테고리의 다른 글
| Gmarket Hadoop Platform Baikal 소개 (0) | 2022.12.27 |
|---|---|
| Kafka 이벤트 모니터링이란.. (먼산) (0) | 2022.10.19 |
| 지마켓 대기열 시스템 파헤치기 (0) | 2022.09.30 |
| 레거시 시스템의 성능과 정합성 두 마리 토끼 잡기 (0) | 2022.09.21 |
| 프로젝트 관리를 위한 JIRA 활용기 (0) | 2022.09.16 |